We didn't build Equus for the AI market. The AI market arrived for us.
We build what AI runs on
We build for where you are. The workstation you train on. The cluster you validate against. The infrastructure you deploy to. Purpose built, every time.
Standard compute works
until your workload
doesn't fit the catalog.
The IT industry built something remarkable: 30 years of standardization that made enterprise compute reliable, scalable, and predictable. Standard form factors. Standard protocols. Standard operating environments. Standard support models. That discipline is genuinely right for the problems it was designed to solve. AI workloads are a different problem entirely. Energy density up to 10x what standard data centers were designed for. GPU components backordered months on the open market. Performance that only surfaces under real inference load, not a benchmark. IP that can’t leave the perimeter. Standard hardware was never designed to survive the harsh or specialized conditions found on factory floors, hospital racks, vehicles, and in air-gapped facilities. Equus has spent 35 years solving exactly these kinds of constraints in telco, defense, and industrial compute. The constraints have new names. The discipline is the same.
Standard compute
Standardized SKUs optimized for high-volume manufacturing, not model performance. Your software must adapt to their hardware limitations.
Purpose built. One for every phase
Architecture engineered around the model you are actually running. We optimize for VRAM, thermal density, and interconnect bandwidth before we ship.
Every buyer in AI infrastructure is navigating the same two forces.
Your infrastructure must survive a landscape that will look completely different in 18 months. Equus is built to adapt with you, not require a vendor replacement when the model stack shifts.
The risk imperative
The greatest cost isn’t a spec mismatch. It’s the supply chain and energy constraints that stop deployments entirely. We navigate the hurdles that Tier-1 OEMs won’t.
WHAT WE BUILD
The hardware changes at every phase.
We build for all of them.
The mission is the same across all of them. The form it takes depends on the environment.
HPC Servers & GPU Clusters
AI factories · Training infrastructure · Large-scale inference
For model training, large-scale inference, and sovereign AI build-outs where your IP stays inside the perimeter. Liquid-cooled, GPU-dense, and rack-optimized units are benchmarked against your actual workload before shipping.
GPU Compute Nodes
HPC Rack Systems
Liquid Cooling
Storage Arrays
Edge Inference Nodes & Endpoints
Field AI · On-premises inference · Ruggedized deployments
For models that have to run inside the hospital, on the factory floor, in the vehicle, inside the bank network where cloud latency fails and data sovereignty is non-negotiable.
Edge Inference Appliances
Ruggedized Nodes
In-Vehicle Compute
5G MEC Platforms
AI & HPC Workstations
Local inference · HPC research · Clinical AI · Developer compute
For researchers, engineers, clinicians, and analysts who need local model inference without the data center. Validated for the models they actually run. The data stays on the machine.
GPU Workstations
Clinical AI Terminals
Research Compute
Local LLM Inference
Retrofits & Upgrades
GPU upgrades · Liquid cooling conversions · Architecture work
You don’t have to start over. From GPU retrofits and liquid cooling to memory and network upgrades, we handle the specialized work Tier-1 OEMs won’t. Built around what you already own.
GPU Retrofits
Liquid Cooling Conversion
Memory Upgrades
Power & Thermal
You build the intelligence.
We build the environment.
From the training workstation to the global inference node, we build the hardware layer your IP requires. Not a catalog SKU, but a purpose-built platform managed through year five. We provide the engineering depth a Tier-1 OEM won’t.
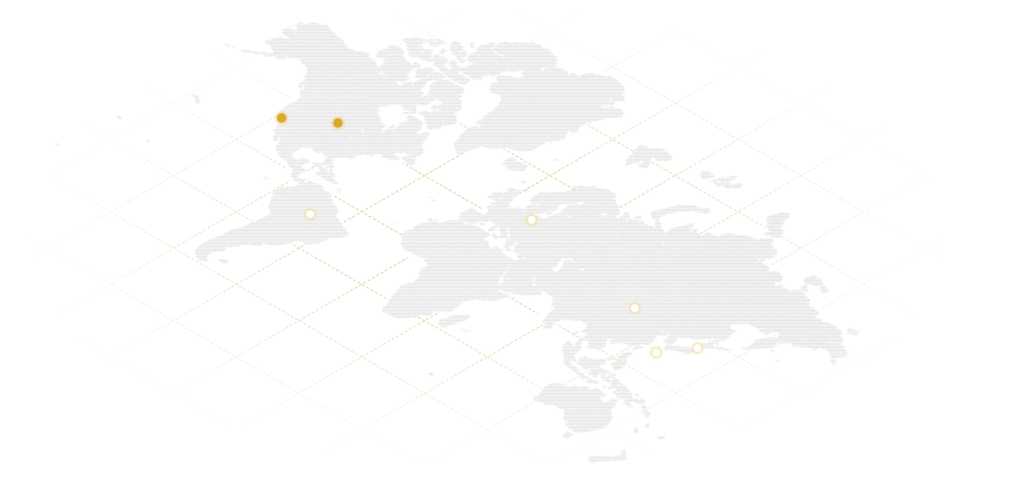
Scale globally without the friction. With physical Equus entities across three continents, we provide local engineering and on-site support in every major market. No resellers, no distributors. US-origin hardware, globally deployed and locally supported.
One partner. Zero variance. Every system originates from US manufacturing to meet strict data sovereignty and government requirements. With dedicated Equus entities across Europe, Asia-Pacific, and South America, you can scale globally while maintaining the same hardware standards, security protocols, and primary point of contact.
For the Developer & Technical Buyer
Built for the model
you're actually running.
Hardware isn’t just a GPU, it’s VRAM, thermals, and bandwidth. Fine-tuning, inference, and edge deployments all have unique requirements. We solve for these specific constraints, not generic categories. Tell us your model, stack, and environment. We’ll build what you actually need.
Corporate headquarters, manufacturing, and employee-owned operations. The source of every system Equus builds. 35 years of US-origin hardware production and supply chain management.
🇺🇸
United States — Integration Center
Los Angeles, California
95,000 sq ft of validation infrastructure. Where your model runs against real hardware before anything ships. Engineering, solutions architecture, and workload validation for every deployment Equus builds.
🇩🇪
Europe
Europe
When your US deployment needs to run in Europe, Equus European Operations is your local support presence. GDPR-compliant programs, on-site lifecycle management, and the same hardware standards across the EU without finding a new hardware partner at the border.
🇧🇷
South America
South America
Your South American deployment supported by an Equus entity on the ground. Local installation, lifecycle management, and hardware support across the region, so your US-built infrastructure runs the same way in South American Operations as it does in Minneapolis.
🇨🇳
Asia — Supply Chain
Asia-Pacific
Component sourcing and supply chain relationships across Asia-Pacific. When GPU allocation is constrained and standard channels are backordered, our Asia presence strengthens sourcing depth for US-based customers without changing hardware provenance.
🇹🇼
Taiwan — Component Sourcing
Asia-Pacific
Supplier relationships at the component level built over 35 years. The allocation access that matters when lead times on the open market are running 9 months. Part of the supply chain depth that keeps US-based customer programs moving.
🇯🇵
Asia — Deployment & Support
Asia-Pacific
When your deployment needs to run across Asia-Pacific, Equus has local presence for on-site support, lifecycle management, and program continuity. The same hardware, the same standards, supported in region.
University labs don’t buy in volume; they buy for the mission. We design custom GPU, memory, and interconnect configurations that the Fortune 500 OEMs won’t touch.
Don’t replace your aging HPC infrastructure, retrofit it. We provide cost-effective paths to GPU-density while maintaining FERPA and DoD research compliance.
Are you an ISV?
We become the hardware layer beneath your product so you never have to become a hardware company.
We didn’t just learn AI. We’ve spent 35 years solving its underlying problems. From custom builds and workload validation to supply chain integrity and lifecycle support, the industry has changed, but the fundamental engineering challenges have not. We’ve mastered the infrastructure journey so you don’t have to.
SYSTEM DELIVERED
0M
35 years of supply chain authority. We navigate the disruptions that stop the Tier-1 OEMs.
EMPLOYEE OWNED
0%
Structural independence. We prioritize long-term stability and support over short-term exit timelines.
SQ. FT. INTEGRATION FACILITY
0K
Real hardware validation. Your actual model tested to failure in our facility, not yours.
UNITS
1-0K
The “Un-served” Tier. We specialize in the quantities hyperscalers won’t touch and OEMs won’t customize.
GPU RETROFITs
Current-gen accelerators in your existing chassis. Skip 12-month lead times.
“Zero new procurement. 4x inference throughput.”
Liquid Cooling Conversions
Direct-to-chip or rear-door cooling for air-cooled racks.
“Power draw down 30%. Density doubled.”
Memory & Network Upgrades
HBM, NVMe, and 400G Ethernet retrofits to break interconnect bottlenecks.
“Diagnosed and resolved in two weeks.”
Power & Thermal Remediation
Facility assessment for 120kW density. We architect the building to fit the cluster.
“Equus told us the building couldn’t support it and fixed that first.”
Full Architecture Reviews
Current-gen accelerators in your existing chassis. Skip 12-month lead times.
“They told us what NOT to upgrade, and what to focus on first.”
Don’t replace your infrastructure, modernize what you already own.
“The Tier-1 OEM said our existing infrastructure couldn’t support the model workload. Equus came in, assessed it, and had us running in six weeks. No new servers.”
The conversation we have most often
Our People
Not a vendor.
A team of owners.
As a 100% employee-owned company, Equus prioritizes the long-term integrity of your deployment over a VC’s exit timeline. This ownership culture ensures our team maintains a personal stake in your success. You are partnering with a company built to stand behind your hardware at year five and beyond.
Rick Green
Chief Executive Officer
Crystal Welna
Chief Human Resources Officer
Jeff Krueger
VP of Technology
Jim Sorboro
Chief Financial Officer
Tim Poor
VP of Channel Sales
Kevin Amiri
VP of Operations
Jason Myers
Chief Revenue Officer
"How do I protect the employees who helped me build this business? How does the legacy of my company endure?"
Andy Juang, Founder — on the 2007 decision to become an ESOP
Tell us your model, your quantization, your serving framework, and where it needs to run. We’ll tell you exactly what hardware it needs and validate it before it ships.